
Faire du café grâce au microcontrôleur MAX78000 et à une pincée d'IA
sur
Le matériel moderne permet d'accélérer la mise en œuvre et le fonctionnement des réseaux neuronaux convolutifs (CNN), généralement utilisés pour analyser des contenus d'images ou de sons. Pour une application, ces dispositifs inaugurent une nouvelle façon de traiter les données et d'interagir avec l'environnement. Le traitement de données requis pour un CNN est énorme pour une seule unité centrale et il peut être lourdement paralysant ; d'où la présence d'un accélérateur. Pour votre PC, il peut s'agir de votre carte graphique ou de systèmes d'accélération spéciaux comme les cartes NVIDIA Tesla (ces accélérateurs sont parfois intégrés au système lui-même, comme avec le nouveau processeur M1 d'Apple). Le microcontrôleur MAX78000 de Maxim Integrated associe un accélérateur CNN, un processeur Cortex-M4F et un cœur RISC-V, comme l'indique la fiche technique. Destiné à traiter les CNN tout en fonctionnant en mode basse consommation, ce microcontrôleur offre de nouveaux moyens d'intégrer l'IA dans les dispositifs embarqués.

Mes collègues d'Elektor ayant déjà décrit le matériel dans deux autres articles [2][3], je vais donc aborder, dans cet article, le logiciel nécessaire à la mise en route du MAX78000. Nous allons également entraîner un CNN à reconnaître certains mots-clés et réaliser quelques interactions matérielles. La carte MAX78000FTHR (figure 1) que j'utilise est proposée dans l'e-choppe Elektor.
À titre d'étude de faisabilité, nous allons modifier l'exemple de reconnaissance de mots-clés pour créer une cafetière à commande vocale. Le COVID-19 poursuivant son voyage autour du monde, les appareils de bureau partagés, une cafetière par exemple, servent de véritable plaque tournante pour la diffusion du virus. Une cafetière que l'on peut commander sans toucher un bouton sera notre démonstration du flux logiciel appliqué au MAX78000. Le SDK fourni permet de programmer en C ou C++. La documentation est accessible dans le référentiel GitHub de Maxim pour le MAX78000.
Deux faces d'une même pièce
Incorporer de l'IA dans des appareils embarqués nécessite un éventail inédit de compétences, selon votre domaine technique d'origine. Les plus avertis en matière de création de réseaux neuronaux auront généralement du mal à entrer dans le monde du développement d'applications embarquées. Si vous connaissez le développement de solutions embarquées et que vous vous lancez dans l'IA, vous rencontrez sans doute aussi des difficultés. Mais si vous décidez d'utiliser des réseaux pré-entraînés à partir d'échantillons, votre machine de développement aux performances moyennes suffira probablement.
Nous allons donc essayer de nous frayer un chemin dans les deux domaines (les réseaux neuronaux et les applications embarquées), en commençant par l'entraînement d'un réseau neuronal. Pour simplifier la démarche, nous allons modifier un exemple existant plutôt que de partir de zéro. Nous nous ferons ainsi une idée des outils utilisés.
Le développement embarqué, et donc la mise en œuvre dans le MAX78000 lui-même, fera l'objet d'une deuxième étape. Si vous découvrez les applications embarquées, il y aura sans doute quelques difficultés à prévoir. D'où la description des concepts clés dans deux articles. Le premier sera consacré à l'IA, le deuxième au développement avec le MAX78000.
Les processeurs graphiques compatibles CUDA sont recommandés
Si vous avez choisi de vous lancer dans les réseaux neuronaux et leur création, un élément doit être pris en compte en priorité. Pour entraîner les réseaux neuronaux pour le MAX78000, il est fortement recommandé d'utiliser un processeur graphique (GPU) compatible NVIDIA CUDA dans votre système. Comme les GPU AMD et Intel ne prennent pas en charge les frameworks d'entraînement de réseaux neuronaux profonds comme Tensor Flow et PyTorch, Nvidia CUDA est le GPU de choix. Et même si vous disposez d'un GPU compatible NVIDIA CUDA, il doit s'agir au minimum d'une puce de la génération Maxwell (série NVIDIA GTX 9) ou d'un NVIDIA Tesla K80.
Au moment où j'écris ces lignes, début 2021, les nouveaux GPU sont coûteux, ce qui peut être un facteur à prendre en considération. Vous pouvez contourner ce problème tout simplement en utilisant votre CPU pour effectuer tous les calculs liés aux réseaux neuronaux, mais cela multipliera au moins par 10 le temps nécessaire.
Cafetière intelligente avec un MAX78000
Modifier une cafetière est à la portée de la plupart d'entre nous, mais pour différentes raisons. Peut-être avez-vous conçu des modifications comme l'ajout d'une fonction Wi-Fi et l'incorporation d'une nouvelle fonction pour réaliser des infusions ? Ou peut-être avez-vous réparé une machine cassée et ajouté quelques améliorations ? L'étude de faisabilité présente est loin d'être parfaite, mais elle doit réaliser les fonctions suivantes :
- La machine doit reconnaître « Happy » comme son nom.
- Demander si elle doit préparer un café.
- Demander si une tasse est insérée.
- Assurer le retour d'information vers l'utilisateur par le biais d'un écran LCD.
Le matériel est assez simple. Nous avons besoin des éléments suivants :
- Carte MAX78000FTHR RevA (figure 1)
- Carte d'essai
- Cavalier
- Écran TFT 2,2" disponible dans l'e-choppe Elektor (figure 2)

Figure 2 : L'écran LCD.
S'il manque une cafetière dans cette liste, sachez que nous avons pris soin de ne blesser aucun appareil en état de marche de ce type lors de la réalisation de cette présentation. Comme il s'agit d'une étude de faisabilité, l'intégration dans une cafetière réelle dépend du fournisseur, et celle que nous utilisons ici est virtuelle. Cette réalisation concerne les principes de base.
Entraînement et synthèse
Maxim propose quelques exemples pour entraîner les réseaux neuronaux convolutifs utilisés dans leurs processus. Vous trouverez un guide des logiciels nécessaires sur la page GitHub de Maxim. Gardez à l'esprit que nous sommes dans l'environnement Linux et que vous devez disposer d'une carte graphique compatible NVIDIA CUDA. Ainsi, pour la démonstration kws20_demo, 3,5 heures ont été nécessaires sur une NVIDIA GeForce GTX 1050Ti et une AMD Ryzen 2700X avec l'accélération CUDA.
Quelques pilotes expérimentaux permettent d'utiliser le sous-système Windows pour Linux afin d'accéder à l'accélération CUDA. Cependant, pour des raisons de stabilité, il est recommandé de s'en tenir à une variante de Linux Debian comme Ubuntu. Ainsi, pour cette partie, des instructions seront données pour effectuer une nouvelle installation d'Ubuntu 20.04 et des outils fournis par Maxim.
La première étape après l'installation est d'obtenir les pilotes propriétaires NVIDIA installés pour avoir accès à l'accélération CUDA. Pour Ubuntu, utilisez l'écran Software & Updates et pour votre carte, ajoutez les pilotes appropriés indiqués sous l'onglet Additional Drivers. Pour la carte GTX1050Ti, le pilote nécessaire apparaît dans la figure 3.
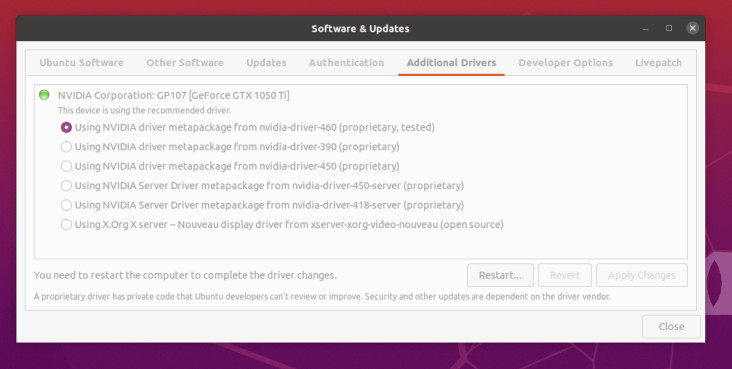
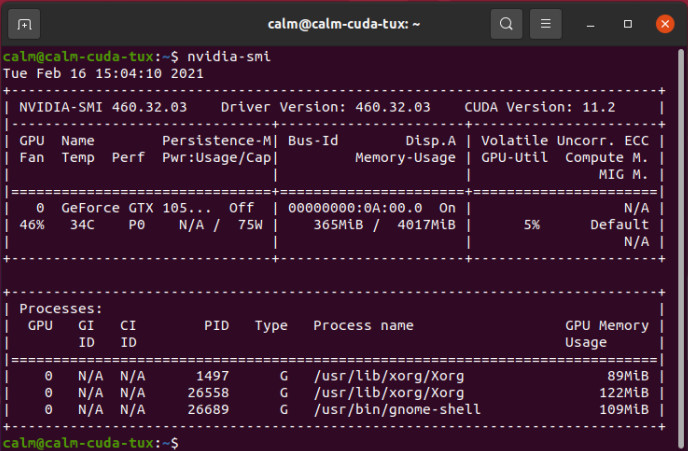
Vous devrez redémarrer votre système. Si, ensuite, il affiche toujours un contenu d'écran, c'est que le pilote NVIDIA fonctionne. Vous pouvez le vérifier avec l'outil nvidia-smi en utilisant une fenêtre de console, comme indiqué dans la figure 4, ce qui vous permettra de connaître la version CUDA utilisée (dans ce cas 11.2).
Pour l'installation du logiciel, suivez le guide que Maxim fournit ici. En suivant dans le manuel la démarche relative à Linux, vous pourrez réaliser l'entraînement du réseau neuronal sur votre machine. La dernière étape du kit de développement de logiciels embarqués permet quelques raccourcis. Il est possible d'installer le compilateur ARM dans Ubuntu en utilisant sudo apt install gcc-arm-none-eabi. Dans ce cas, il n'est pas nécessaire d'ajouter le compilateur ARM au fichier ~/.profiles file. Pour le compilateur RISC V, la version actuelle, au moment où nous écrivons ces lignes, est la 10.1. Nous recommandons d'effectuer une copie et d'extraire les fichiers dans votre dossier personnel. Il suffit d'ajouter les lignes suivantes à votre fichier ~/.profiles :
echo $PATH | grep -q -s "~/xpack-riscv-none-embed-gcc-10.1.0-1.1/bin"
if [ $? -eq 1 ] ; then
PATH=$PATH:~/xpack-riscv-none-embed-gcc-10.1.0-1.1/bin
export PATH
RISCVGCC_DIR=~/xpack-riscv-none-embed-gcc-10.1.0-1.1/
export RISCVGCC_DIR
fi
Vous pourrez ainsi effectuer les entraînements du réseau. La deuxième partie nécessaire est l'étape de synthèse. La synthèse permet de transformer un réseau entraîné en quelque chose d'utilisable par le MAX78000. Pour la mettre en œuvre, vous pouvez accéder au manuel d'installation ici. Comme vous avez déjà installé la partie relative à l'entraînement, passez directement à la section Upstream Code dans le manuel.
Si vous m'avez suivi jusqu'ici, vous allez pouvoir entraîner et synthétiser des modèles exploitables avec le MAX78000. Cela signifie également que vous pouvez modifier les scripts afin d'entraîner de nouveaux éléments pour qu'ils soient reconnus s'ils existent dans les données d'entraînement.
Modifier et entraîner l'exemple de repérage de mots-clés
L'un des exemples proposés est le repérage de mots-clés. Comme déjà mentionné dans l'article de Clemens Valens, la démo écoute un ensemble de 20 mots qui ont fait l'objet d'un entraînement préalable. Ces mots sont « up, down, left, right, stop, go, yes, no, on, off, one, two, three, four, five, six, seven, eight, nine, zero »* et sont choisis parmi un ensemble de 31 mots qui peuvent faire l'objet d'un entraînement par un utilisateur.
*haut, bas, gauche, droite, arrêt, action, oui, non, actif, inactif, un, deux, trois, quatre, cinq, six, sept, huit, neuf, zéro.
La liste complète des mots-clés reconnus « backward, bed, bird, cat, dog, down, eight, five, follow, forward, four, go, happy, house, learn, left, marvin, nine, no, off, on, one, right, seven, sheila, six, stop, three, tree, two, up, visual, wow, yes, zero »**.
**en arrière, lit, oiseau, chat, chien, en bas, huit, cinq, suivre, en avant, quatre, action, happy, maison, apprendre, gauche, marvin, neuf, non, inactif, actif, un, droite, sept, sheila, six, arrêt, trois, arbre, deux, en haut, visuel, ouah, oui, zéro.
Pour notre démonstration, nous nous en tenons au nombre de 20 mots-clés que nous souhaitons reconnaître, mais nous utiliserons « marvin, happy, backward, forward, stop, go, yes, no, on, off, one, two, three, four, five, six, seven, eight, nine, zero ».
***marvin, happy, en arrière, en avant, arrêt, action, oui, non, actif, inactif, un, deux, trois, quatre, cinq, six, sept, huit, neuf, zéro.
Pour modifier la liste, nous naviguons dans notre dossier ai8x-training sur la machine Ubuntu installée (voir la figure 5).
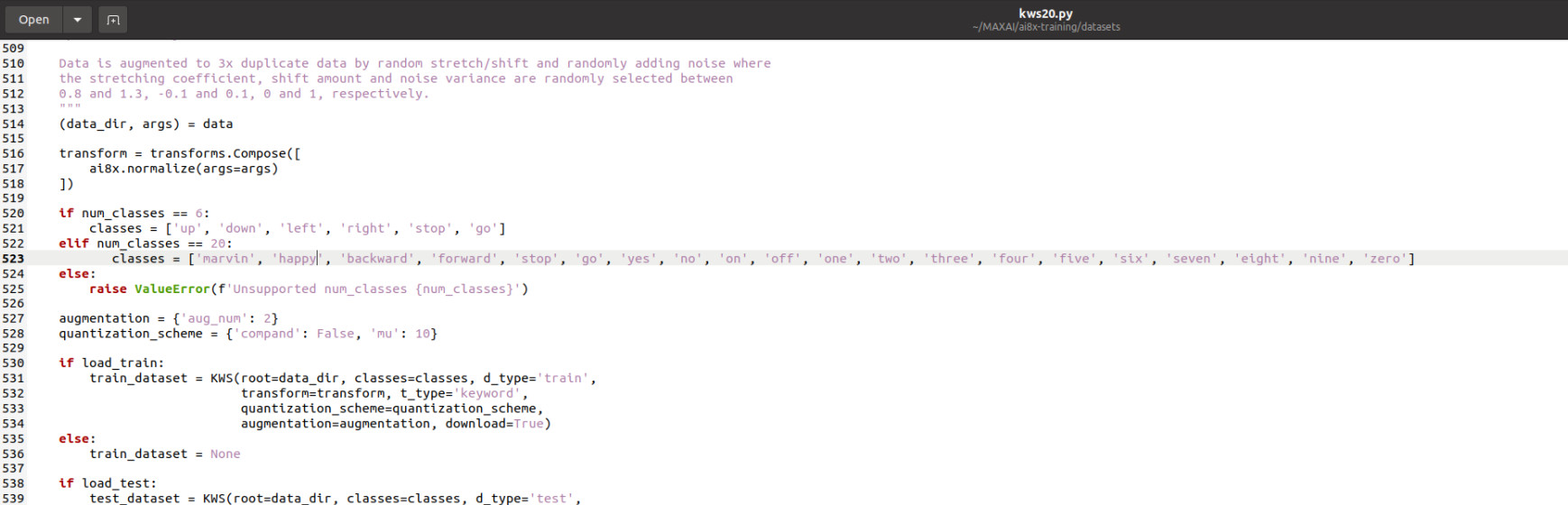
Dans le dossier, nous allons modifier le fichier ./datasets/kws20.py, comme le montre la figure 6.
De là, nous pouvons ouvrir un terminal et accéder au dossier ai8x-training. Pour obtenir le CNN avec le nouvel ensemble de mots-clés, nous démarrons l'entraînement avec ./scripts/train_kws20_v3.sh.
À ce stade, l'entraînement peut commencer et nécessiter un certain nombre d'heures voire de jours, selon votre matériel. À la fin de l'entraînement, vous trouverez dans ./logs/ un nouveau dossier avec l'heure et la date comme nom et qui contient les résultats de l'entraînement. Ces résultats devront être synthétisés pour être utilisés par le MAX78000.
Synthèse des données
Une fois l'entraînement terminé, les informations doivent être mises sous une forme que le MAX78000 pourra charger. Nous devons entrer dans le dossier ai8x-synthesis pour déplacer et supprimer les fichiers. Pour être sûr qu'aucune ancienne donnée ne sera utilisée, supprimez le contenu du dossier trained. Copiez le fichier best-pth.tar depuis le dossier ai8x-training/logs/{start time}/ vers le dossier ai8x-synthesis/trained/ car nous avons besoin des deux fichiers pour la suite du traitement. Démarrez un terminal et accédez à votre dossier ai8x-synthesis.
Exécutez source bin/activate pour configurer l'environnement Python. Nous pouvons maintenant effectuer une quantification de notre modèle entraîné copié avec ./quantize.py trained/best.pth.tar trained/ai85-kws20-v3-qat8-q.pth.tar –device MAX78000 -v dans un fichier quantifié appelé ai85-kws20-v3-qat8-q.pth.tar, dans le dossier trained. Après la quantification, nous pouvons générer du code et les fichiers finaux utilisables pour le MAX78000.
L'étape finale sera la génération de code pour une utilisation ultérieure. Dans le terminal encore ouvert, tapez les éléments suivants : ./ai8xize.py --verbose --log --test-dir ~/MAX78000/ --prefix kws20_v3 --checkpoint-file trained/ai85-kws20_v3-qat8-q.pth.tar --config-file networks/kws20-v3-hwc.yaml --softmax --device MAX78000 --compact-data --mexpress --timer 0 --display-checkpoint --board-name FTHR_RevA
Un dossier MAX78000 sera ainsi généré dans le répertoire d'accueil. Il contiendra une petite application élémentaire qui se teste elle-même avec pour référence des données de test prédéfinies dans le code. Cette application se trouvera dans un dossier kws20_v3, avec les fichiers weights.h, cnn.h et cnn.c, contenant le CNN et ses fonctions. À ce stade, le développement embarqué peut commencer, car nous devrions maintenant avoir un CNN qui pourra écouter nos mots-clés modifiés.
Lectures supplémentaires
Vous voulez aller un peu plus loin dans l'univers des CNN ? Commencez par l'introduction proposée ici. En suivant le tutoriel, vous comprendrez un peu mieux ce que font les scripts et les entraînements. En outre, [12] vous donnera quelques idées de base sur les mathématiques internes des CNN et pourquoi les utiliser. Ces informations faciliteront votre parcours dans ce domaine.
Les outils fournis par Maxim fonctionnent avec PyTorch et TensorFlow, qui n'offrent une compatibilité complète CUDA que pour les GPU NVIDIA. En vous armant d'un peu de courage, vous pourrez utiliser ROCm d'AMD. Il s'agit d'une version modifiée de PyTorch qui permet l'accélération pour certains GPU AMD. Certains éléments sont intégrés à l'UC AMD, mais ils sont expérimentaux et officiellement non pris en charge.
MAX78000 : pour aller plus loin
Comme nous sommes maintenant capables d'entraîner de nouveaux CNN pour le MAX78000, nous allons passer à l'aspect embarqué du projet. Pour le développement, nous utiliserons les outils fournis par Maxim. Il est possible de télécharger l'IDE Eclipse sur la suite web de Maxim. Pour mon développement, ces outils ont également bien fonctionné sur une machine virtuelle. Si un imprévu survient, ou si vous devez changer de machine de développement, il suffira de déplacer certains fichiers depuis la machine virtuelle. En prime, vous pouvez également effectuer, si nécessaire, des captures d'écran de votre environnement de développement. À ce stade, la mise au point de notre cafetière se fera en C pur. En attendant, vous pouvez déjà jeter un coup d'œil à la documentation MAX78000 et au guide de l'utilisateur du MAX78000. Gardez à l'esprit que la documentation est encore en cours de développement. Ainsi, si vous pensez qu'il manque quelque chose, vous pouvez laisser une note sous forme de problème GitHub ou nous contacter sur la page www.elektormagazine.fr/labs/MAX78000.
Des questions ? Des commentaires ?
Avez-vous des questions ou des commentaires techniques à propos de cet article ? N'hésitez pas à envoyer un courrier électronique à l'auteur à l'adresse mathias.claussen@elektor.com ou contactez Elektor à l'adresse editor@elektor.com.
L’intelligence artificielle (IA) a encore besoin de l’intelligence naturelle pour innover, autrement dit a besoin de votre talent !
Et puisque le talent se récompense, Elektor organise un concours vous invitant à imaginer et concevoir une application originale pour le microcontrôleur MAX78000 à ultra-basse consommation de Maxim Integrated.

Traduction : Pascal Godart
Discussion (0 commentaire(s))